|
在实际业务生产环境中,业务应用系统在使用 OLTP 数据库将数据进行存储后,均会存在如后台运营类系统进行统计报表分析等场景的复杂 SQL 查询诉求。
为满足此类复杂 SQL 查询快速响应的需求,DRDS 团队基于第三代分布式SQL引擎,进一步引入自研 MPP 多机并行计算引擎(Fireworks)及对应的优化策略,极大地补强了 DRDS 的复杂查询处理能力。

千万级数据下的分布式多表Join、聚合、排序、子查询操作秒级返回结果,可极大的提升响应速度。自身利用同一份数据(RDS只读)进行处理,无需数据同步至其他数据源,降低业务架构整体链路复杂度,节省业务运维及预算成本。
主要特性
自研 MPP 多机并行计算引擎 Fireworks
DRDS 只读实例搭载了一个具备完整多机并行处理能力的 SQL 执行引擎(Fireworks)。它与 DRDS 主实例上搭载的 SQL 执行引擎有显著差异。
DRDS 主实例的执行引擎采用单机架构,采取尽可能将计算下推至底层各物理分库执行的策略,依靠物理分库的计算能力实现了逻辑SQL的分布式计算。
而 DRDS 只读实例上搭载的 Fireworks 引擎是一个由多个计算节点组成的集群,将一个 SQL 查询转换为一个分布式计算任务,突破下挂 物理库计算能力的限制,大幅提升针对复杂逻辑SQL的计算速度,对 Join、Aggregate 和 Sort 计算有显著加速效果。
Fireworks 会将 Join、Aggregate 和 Sort 这类计算任务通过 Shuffle 的方式打散并分发到计算集群的多个计算节点上,通过多计算节点并行计算达到计算加速的目的。
针对多机并行执行模式定制打造的优化器
原 DRDS 主实例优化器主要侧重 OLTP 场景,核心理念是尽量将一切计算下推至下挂的物理库执行。其目的是充分利用物理库的计算资源,同时可以避免产生大量的数据流动,从而得到较快的响应速度。
而当面对涉及较大数据量级下的复查查询场景时,整体性能会受到下挂物理库的限制,同时也会对物理库产生较大的压力从而影响稳定性,总体来看其 OLAP 能力有很多局限性。
在引入了 MPP 多机并行计算引擎 Fireworks 之后,DRDS 本身在计算能力上得到了极大地提升,优化器的整体优化策略也有所调整:
- 尽量将复杂计算(如 Join 、Aggregation 、Sort )上提至自身执行引擎计算,通过 Fireworks 计算集群实现计算加速与可扩展性;
- 将轻量级的计算(如 Project 、Filter )继续下推至至物理库从而减少数据拉取的成本。
DRDS 分布式 SQL 优化器通过对执行计划最细粒度的优化可以产生出对多机并行执行引擎友好的执行计划,获得更好执行效率。
同时提供精细化算子下推策略,将对 RDS 较小压力的算子下推至物理库取得更高的计算性价比,同时保护 RDS 免受代价较大算子的影响,从而保证在线流量的稳定性。
基于在线数据直接分析
以新零售业务为代表的新兴互联网业务不断涌现,这类业务除了有实时的 OLTP 需求,还伴随着一些有一定复杂度的准实时 OLAP 的需求用以支持实时决策等需求。
而目前大多数的数据分析场景的解决方案均需要将 OLTP 数据库的生产数据导出至其他数据源进行再次离线分析,这种传统方案很难满足准实时的需求,同时在数据导出至离线系统时也存在数据丢失的风险。
DRDS 只读实例无需进行冗长繁琐的数据同步任务,基于 RDS 只读实例或 RDS 主实例直接进行复杂数据处理,降低业务架构整体链路复杂度,节省业务运维及预算成本。
DRDS 只读实例在避免数据同步的同时,可保证数据处理时效性,最高可做到 READ COMMITED 的实时性 (基于 RDS 主实例)。
边界清晰的 SQL 兼容性
DRDS 只读实例全面兼容 DRDS 主实例的 SQL 查询语法,与 DRDS 5.3 版本的 SQL 兼容性和 SQL 支持边界高度保持一致。
与同类产品相比具备兼容性高以及支持边界清晰的特点。可以提供与 DRDS 主实例几乎一致的体验。
DRDS 主实例上无法执行或执行较慢的复杂 SQL 可以直接迁移到只读实例来执行,免去SQL改写的额外开销。
产品体验灵活自主
DRDS 只读实例自动同步 DRDS 主实例的账号权限信息,原生VPC支持,内外网可同时开启,根据业务情况灵活变配,数据处理能力线性提升。
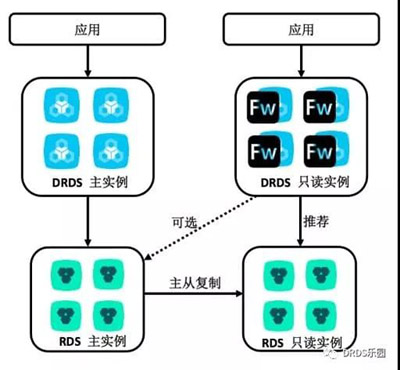
技术架构总览
DRDS 只读实例整体架构与 DRDS 主实例基本保持一致,仅在查询层有所变化,增加了 MPP 执行引擎和对应优化器,如下如所示:

DRDS协议层负责处理网络交互与 MySQL 协议的解析,收到查询请求后会将 SQL 转交至查询层处理。查询层负责解析 SQL 并由执行器产生经过优化的执行计划,然后交由执行引擎到存储层进行查询以及计算。
如果需要使用 Fireworks 引擎计算,在得到执行计划之后查询层还会将该执行计划进一步转换为分布式执行计划并将其作为分布式任务提交给 Fireworks Cluster。由远端的 Fireworks 集群完成到存储层进行数据查询以及后续计算的工作。
简单来说,DRDS 只读实例可以认为是在原 DRDS 基础上增加了一条具备多机并行处理能力的执行链路。
适用场景
总体来说 DRDS 只读实例适用于处理低并发高延迟的大数据量级下的复杂查询。如数据分析及报表类场景,该类场景的典型特征为含有大量的关联、聚合及排序操作且参与计算的数据规模较大。
目前 DRDS 只读实例在阿里集团内部已经落地了多个业务,其中最具代表性的当属盒马、商业大脑等新零售场景。围绕人、货、场、仓多个维度进行关联分析,对分散在不同逻辑库的几张甚至十几张逻辑表进行关联然后再聚合、排序以满足库存对账、决策支持等业务上的需求。
DRDS 只读实例的出现使业务开发同学不再需要配置、维护数量繁多的数据同步链路,不用担心因数据不同步而造成的结果时效性差或不准确等问题,一定程度上减轻了开发同学的工作负担。
对于已经在使用 DRDS 的用户来说,DRDS 只读实例可以解决如下两类已知问题:
在使用 DRDS 过程中可能会发现某一些涉及Join、聚合、排序的复杂 SQL因为不能完全下推而需要在DRDS执行引擎中进行二次计算,而这种计算因为受到单机执行引擎在内存方面的限制而无法执行。
SQL 的复杂计算部分可以下推但是涉及到的数据规模较大造成物理库压力增高影响 OLTP 业务或者响应时间过慢达不到要求。
小结
长期以来 DRDS 受到单机架构执行引擎的限制一直无法对基于大数据规模的复杂查询提供很好的支持,也无法通过扩展物理资源来实现对自身本地计算能力的线性扩展。
DRDS只读实例的推出彻底地弥补了 DRDS 在 OLAP 场景下的短板,使得 DRDS 在提供强大 OLTP 能力的同时提供可扩展的 OLAP 能力,为同时具有 OLTP 需求与中等规模数据分析需求的用户提供了一站式整体解决方案,为用户带来便利。
后续半年时间内 DRDS 只读实例将发布跨逻辑库的关联查询功能,并通过更多的技术手段,不断增强只读实例核心能力,在并发度、响应时间、数据量、交互式查询等方面将拥有更好的表现,满足企业级应用对数据库的严苛要求。
|



